OpenELM 反映了 Microsoft 为使本地运行的小型人工智能语言模型发挥作用所做的努力。

在 AI 领域所谓的”小型语言模型”(small language models)最近越来越受欢迎,因为它们可以在本地设备上运行,而不需要云端的数据中心级计算机。而苹果公司推出了一套名为”OpenELM“的小型源代码 AI 语言模型,其体积小到可以直接在手机上运行,这些模型目前主要是概念验证研究模型,但它们可能成为苹果公司未来设备上 AI 产品的基础。
苹果公司的新 AI 模型统称为 OpenELM(”开源高效语言模型”),目前可根据苹果示例代码许可证在 Hugging Face 上获取,由于许可证中存在一些限制,它可能不符合公认的”开源”定义,但 OpenELM 的源代码是可用的。
Microsoft 的 Phi-3 模型目标是实现在可本地运行的小型 AI 模型中实现实用的语言理解和处理性能,Phi-3-mini 具有 38 亿个参数,但苹果公司的一些 OpenELM 模型要小得多,发布的 8 个不同模型的参数从 2.7 亿个到 30 亿个不等。
相比之下,Meta 的 Llama 3 系列目前发布的最大模型包含 700 亿个参数(4000 亿个版本即将发布),OpenAI 2020 年发布的 GPT-3 包含 1750 亿个参数,参数数是衡量 AI 模型能力和复杂性的一个粗略标准,但最近的研究重点是让较小的 AI 语言模型也能像几年前的大型模型一样。
这 8 个 OpenELM 模型有两种类型:4 个是”预训练”模型(基本上是原始的、下一个标记版本的模型),4 个是指令调整模型(针对指令跟踪进行了微调,更适合开发 AI 助手和聊天机器人):
- OpenELM-270M
- OpenELM-450M
- OpenELM-1_1B
- OpenELM-3B
- OpenELM-270M-Instruct
- OpenELM-450M-Instruct
- OpenELM-1_1B-Instruct
- OpenELM-3B-Instruct
OpenELM 具有一个 2048 个令牌的最大上下文窗口,这些模型是在公开可用的数据集 RefinedWeb、去除重复内容的 PILE 版本、RedPajama 的子集和 Dolma v1.6 的子集上进行训练的,Tokens 是 AI 语言模型用于处理数据的碎片化表示。
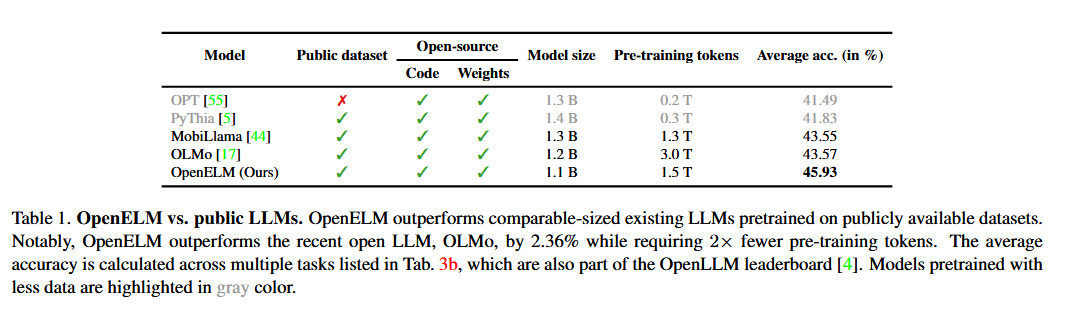
苹果表示,其使用 OpenELM 的方法包括一种”分层扩展策略”(layer-wise scaling strategy),据说这种策略能更有效地在各层之间分配参数,不仅能节省计算资源,还能提高模型的性能,同时还能在更少的 tokens 上进行训练。根据苹果发布的白皮书,与 Allen AI 的 OLMo 1B(另一种小型语言模型)相比,这一策略使 OpenELM 的准确率提高了 2.36%,而所需的预训练标记数量仅为后者的一半。
苹果还发布了用于训练 OpenELM 的库 CoreNet 的代码–其中还包括可复制的训练配方,允许复制权重(neural network files),这在迄今为止的大型科技公司中并不多见。正如苹果公司在 OpenELM 论文摘要中所说,透明度是该公司的一个关键目标: “大型语言模型的可重复性和透明度对于推进开放研究、确保结果的可信度、调查数据和模型的偏差以及潜在风险至关重要”。
苹果公司表示,通过发布源代码、模型权重和培训材料,它旨在 “增强和丰富开放研究社区”。不过它也提醒说,由于模型是在公开来源的数据集上训练的,”这些模型在响应用户提示时有可能产生不准确、有害、有偏见或令人反感的输出”。
虽然苹果尚未将这一新的 AI 语言模型功能整合到其消费类设备中,但据传即将推出的 iOS 18 更新(预计将在 6 月份的 WWDC 上公布)将包括新的 AI 功能,这些功能将利用设备上的处理来确保用户隐私,不过该公司可能会聘请 Google 或 OpenAI 来处理更复杂的、设备外的 AI 处理,从而为 Siri 带来久违的提升。

