Meta 发布了迄今为止最大的开源 AI 模型 – Llama 3.1 405B。
要点一览
- 最新的系列模型将上下文长度扩展到了 128K、增加了对 8 种语言的支持,并包括顶级开源模型 Llama 3.1 405B;
- Llama 3.1 405B 独树一帜,Meta 官方称其可与最好的闭源模型相媲美;
- 此次发布还提供了更多与模型配合使用的组件(包括参考系统)来将 Llama 打造为一个系统;
- 用户通过 WhatsApp 和 meta.ai 就可以体验 Llama 3.1 405B 了。
官网地址:llama.meta.com

Meta 公司发布的这款 AI 模型名为 Llama 3.1 405B ,它拥有 4050 亿个参数。参数数量越多,模型解决问题的能力通常就越强。虽然 Llama 3.1 405B 不是目前所有开源模型中参数最多的,但它是近年来最大的之一。它使用 16,000 个英伟达 H100 GPU 训练而成,并受益于更新的训练和开发技术。Meta 公司声称,即使与一些非开源的顶尖模型(比如 OpenAI 的 GPT-4o 和 Anthropic 的 Claude 3.5 Sonnet)相比,Llama 3.1 405B 的性能也同样出色(当然也存在一些限制)。
Llama 3.1 405B 可供下载或在云平台上使用,目前也可以在 WhatsApp 和 Meta.ai 的聊天机器人中体验。
介绍 Llama 3.1
Llama 3.1 405B 的亮点在于其多语言支持能力和扩展的上下文长度。这个模型支持 8 种语言 (英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语),并且可以处理多达 128,000 个 tokens 的超长上下文,因此能够应对复杂的翻译任务、长篇摘要,甚至需要高级推理的难题。预计它将在商业和研究领域的应用范围大大拓宽。不过,Llama 3.1 405B 不是多模态模型,它仅用于处理文本,无法回答与图像相关的问题。但它可以处理 PDF 和电子表格等基于文本的文件。
为了兑现开源承诺,Meta 将这些模型提供给社区,用户可以在 llama.meta.com 和 Hugging Face 上下载。
Llama 3.1 模型评估
根据今天同时发表的论文,Meta似乎也在进行多模态实验。公司的研究人员写道,他们正在积极开发能够识别图像和视频,并且能够理解(和生成)语音的Llama模型。
Meta在开发Llama 3.1 405B上投入了巨额资金,使用超过 16,000 台 NVIDIA H100 GPU,并用 15 万亿个 tokens(tokens是模型比整个单词更容易内化的单词部分,15 万亿个 tokens 相当于 7,500 亿个词)对模型进行了训练。由于 Meta 之前使用相同的基础数据集训练过早期的 Llama 模型,这本身并不是一个新的训练集,但公司声称在开发这个模型时改进了数据策划管道,并采用了“更严格”的质量保证和数据筛选方法。
公司还使用合成数据(由其他 AI 模型生成的数据)对 Llama 3.1 405B 进行了微调。包括 OpenAI 和 Anthropic 在内的大多数主要 AI 供应商都在探索合成数据的应用,以扩大AI训练规模,但一些专家认为合成数据可能加剧模型偏见,因此对此看法不一。Meta 声称在 Llama 3.1 405B 的训练数据上“谨慎平衡”了数据,但并未透露确切的数据来源。许多生成式AI供应商将训练数据视为竞争优势,因此对相关信息保密。此外,训练数据细节也可能引发与知识产权相关的诉讼,这是公司不愿透露太多的另一个原因。
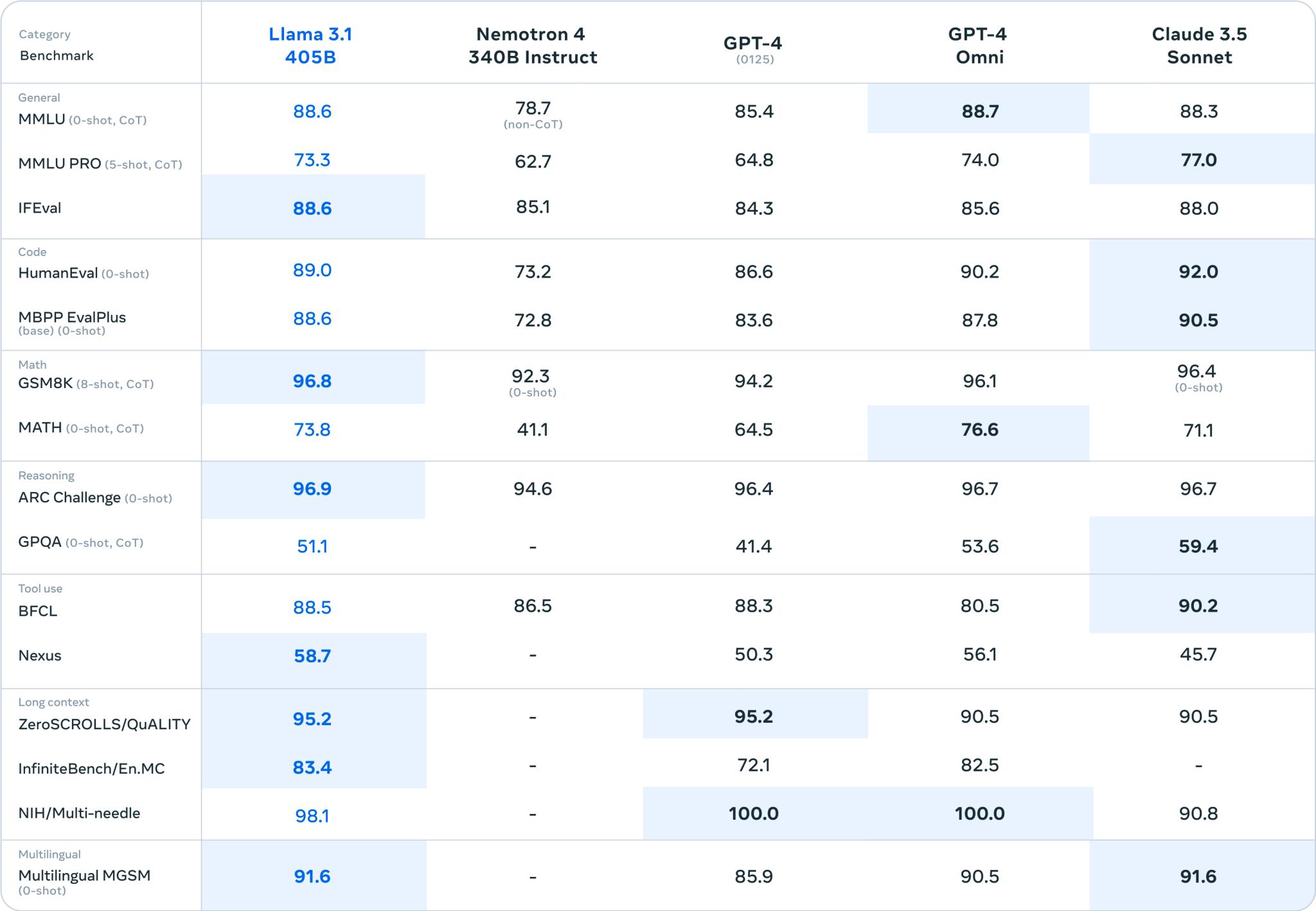
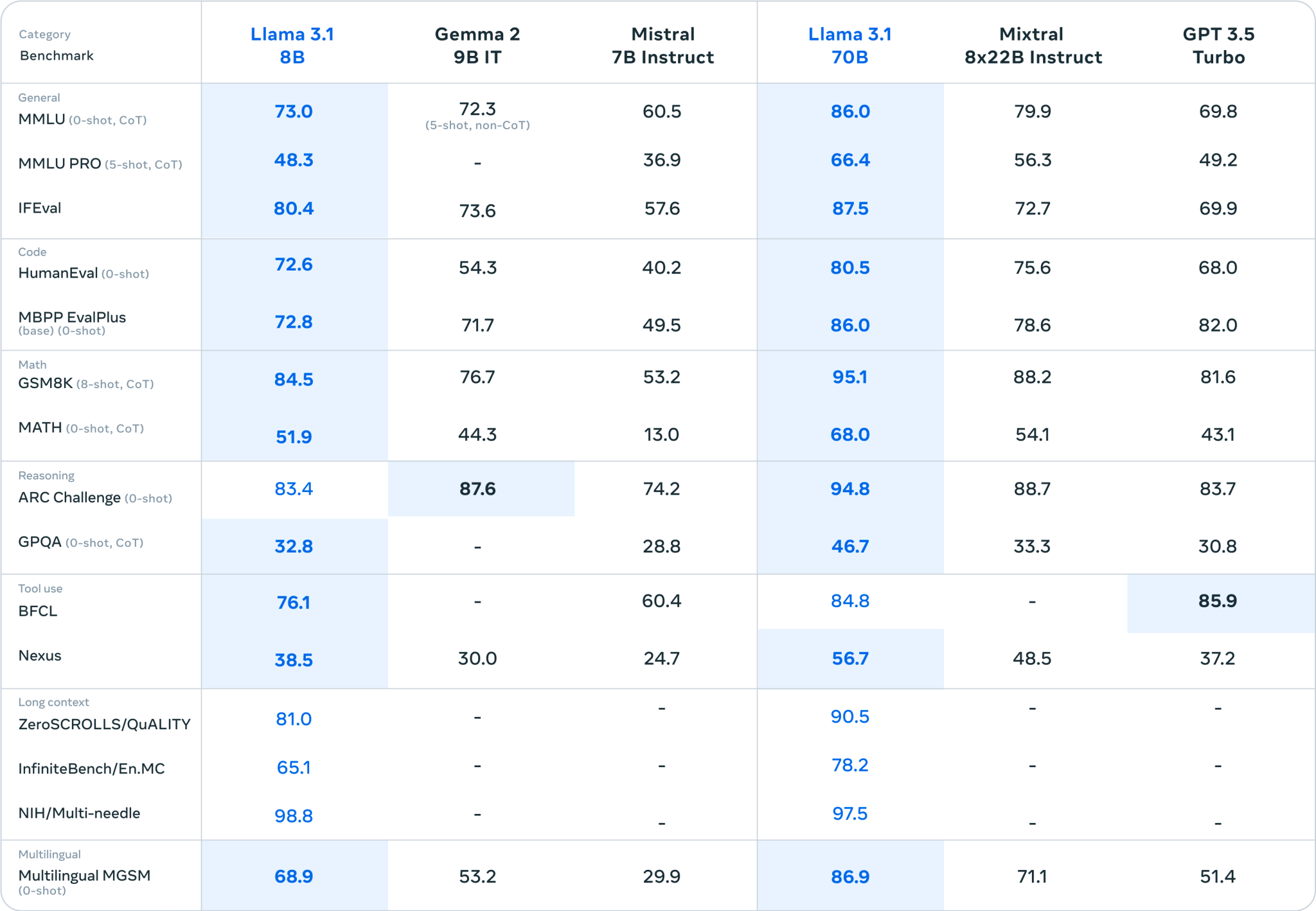
根据 Meta 发布的图表显示,405B 在 MMLU(大学本科知识)、GSM8K(小学数学)、HumanEval(编程)等基准测试上,表现非常接近 GPT-4 Turbo、GPT-4o 和 Claude 3.5 Sonnet。然而,这些基准测试不再是衡量最先进 AI 模型性能的正确指标,业界正在寻求开发新的基准测试方法。
如果基准测试结果可信的话(尽管基准测试并不是生成式 AI 的最终标准),Llama 3.1 405B 的确是一款非常强大的模型。考虑到前几代 Llama 模型的明显局限性,这无疑是一件好事。
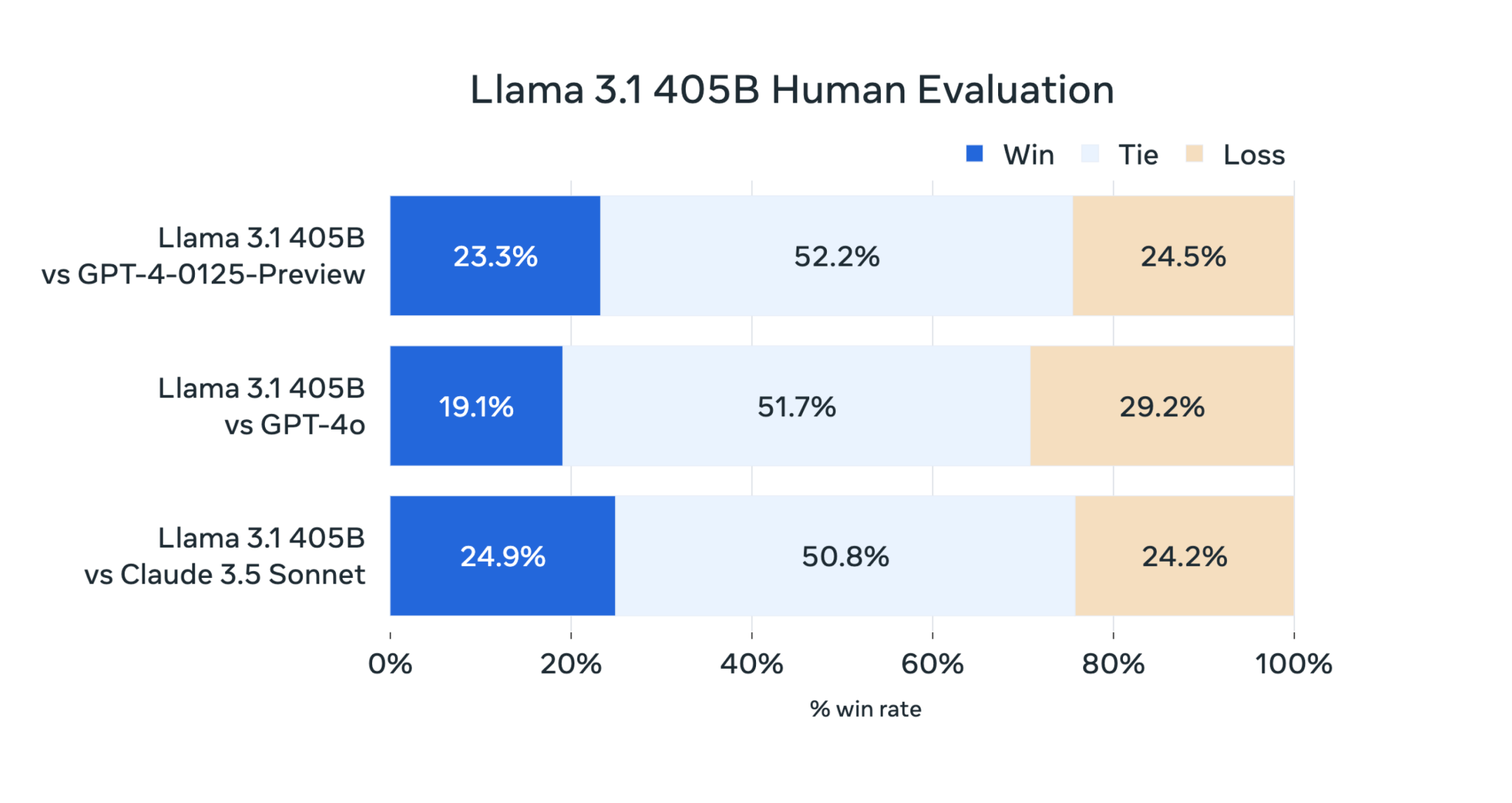
Llama 3 405B 的性能与 OpenAI 的 GPT-4 相当,但根据 Meta 雇佣的人类评估员的反馈,Llama 3 405B 与 GPT-4o 和 Claude 3.5 Sonnet 相比表现“喜忧参半”。论文指出,虽然 Llama 3 405B 在执行代码和生成图表方面比 GPT-4o 更出色,但其多语言能力总体上较弱,在编程和一般推理方面也落后于 Claude 3.5 Sonnet。
由于其体积庞大,运行 Llama 3 405B 需要强大的硬件支持。Meta 建议至少配置一台服务器节点。这可能也是为什么 Meta 更倾向于推动更小的新模型 Llama 3.1 8B 和 Llama 3.1 70B,用于聊天机器人和生成代码等通用应用。公司表示,Llama 3.1 405B 更适合用于模型蒸馏(将大型模型的知识转移到更小、更高效的模型上)和生成用于训练(或微调)其他模型的合成数据。
为了鼓励合成数据的应用,Meta 表示已经更新了 Llama 的许可证,允许开发者使用 Llama 3.1 家族的输出结果来开发第三方生成式 AI 模型(是否明智仍有待商榷)。重要的是,许可证仍然限制开发者如何部署 Llama 模型:每月用户超过 7 亿的应用开发者必须向 Meta 申请特殊许可证,由公司自行决定是否授予。
为了在生成式 AI 领域争得一席之地,Meta 推出了 Llama 3.1 家族的同时,还发布了所谓的“参考系统”和新的安全工具 – 其中一些工具可以阻止可能导致 Llama 模型表现出不可预测或不理想行为的提示,以此来鼓励开发者在更多场景中使用 Llama。公司还预览并征求对 Llama Stack 的意见,这是一个即将推出的 API,用于微调 Llama 模型、使用 Llama 生成合成数据以及构建“代理”,由 Llama 驱动、能够代表用户采取行动的应用程序。
Llama 3.1 的发展潜力
Meta 称,“Llama 3.1 405B 是第一个在一般知识、操作性、数学、工具使用和多语言翻译方面与顶级 AI 模型相媲美的开放可用模型。” Meta的 CEO 马克·扎克伯格称 405B 为“第一个具有前沿水平的开源 AI 模型。”
在 AI 行业中,“前沿模型”指的是为了扩展当前功能极限而设计的 AI 系统。在这种情况下,Meta 将 405B 定位为与 OpenAI 的 GPT-4o、Claude 的 3.5 Sonnet、Google Gemini 1.5 Pro 等顶级 AI 模型相提并论。然而,“开源”这个词的使用存在争议。独立 AI 研究员 Simon Willison 大体支持扎克伯格的说法,但批评“开源”这个词的误用是“一种小规模的文化破坏行为”。Llama 3.1 模型的代码和权重确实是公开的,但下载需要提供联系信息并同意许可协议,这与严格意义上的开源不同。最坏的情况下,Meta 可以随时禁止使用 Llama 3.1 或其输出。
Meta 免费公开这样的大模型背后有复杂的策略。一个目的是建立自己的“AI 生态系统”,吸引开发者。此外,社区对模型的改进也有助于 Meta 产品的提升,还可以牵制像微软和谷歌这样在 AI 领域具有更好基础设施和互补商业模式的企业,防止它们超越 Meta。这个发布还强调了 Meta 和 NVIDIA 的合作扩展。NVIDIA 是 Meta 的重要合作伙伴,通过提供用于训练 Llama 最新版本的 GPU计算芯片,支持了 Meta 的 AI 模型开发。
Llama 3.1 405B 的出现是迈向 AI 未来的重要一步,将进一步激化开源模型与商用模型的竞争。这一发展将如何促进 AI 的进步和对社会的贡献,值得我们关注。









评论前必须登录!
立即登录 注册