英伟达新发布的“Fugatto”模型能够通过创新的合成方法和推理技术,生成各种从未存在过的声音,包括混合音乐、语音和其他声音。虽然模型尚未公开测试,但其展示了许多独特的音频效果,展示了其潜力。

数据决定成败
在一篇解释性研究论文中,超过十位英伟达的研究人员通过利用大型语言模型 (LLM) 生成 Python 脚本,以创建大量描述不同音频“个性”的模板化和自由格式指令。由于广泛开源的 Fugatto 音频数据集通常缺乏特征测量,研究人员借助现有音频理解模型,为训练剪辑创建“合成标签”,并自动量化性别、情感和语音质量等特征。同时,他们还使用音频处理工具在声学层面描述和量化训练剪辑。
在进行关系性比较时,研究人员依赖于在某一因素保持不变时另一个因素变化的数据集,例如相同文本的不同情感朗读。通过比较这些样本,模型能够学习哪些音频特征与“更快乐”的语音相关,或区分不同乐器的声音。
最终,克服了音频和语言之间的关系难题,利用开源数据集和现有音频理解模型,成功训练了 Fugatto 模型。该模型的训练数据集包含 2000 万个样本,代表 50,000 小时的音频,最终得到了一个 2.5 亿参数的模型,能在音频质量测试中表现出良好的评分效果。
英伟达的 Fugatto 模型通过其“ComposableART”系统,能够在给定音频和文本提示的情况下生成前所未有的音频组合。该系统能够根据条件控制音频特征并创造出新声音,例如将吉他声音与笑声结合或将机器声音与痛苦尖叫混合。
英伟达的Fugatto系统引入了名为“ComposableART”的音频表示转换技术,能够在给定文本和/或音频提示时,通过“条件指导”独立控制和生成未见过的指令和任务组合,从而创造出高度可定制的音频输出。这一系统可以将训练集中的不同特征组合,生成全新声音,例如“听起来像笑声的吉他”或“像在轻柔降雨中演奏的班卓琴”。
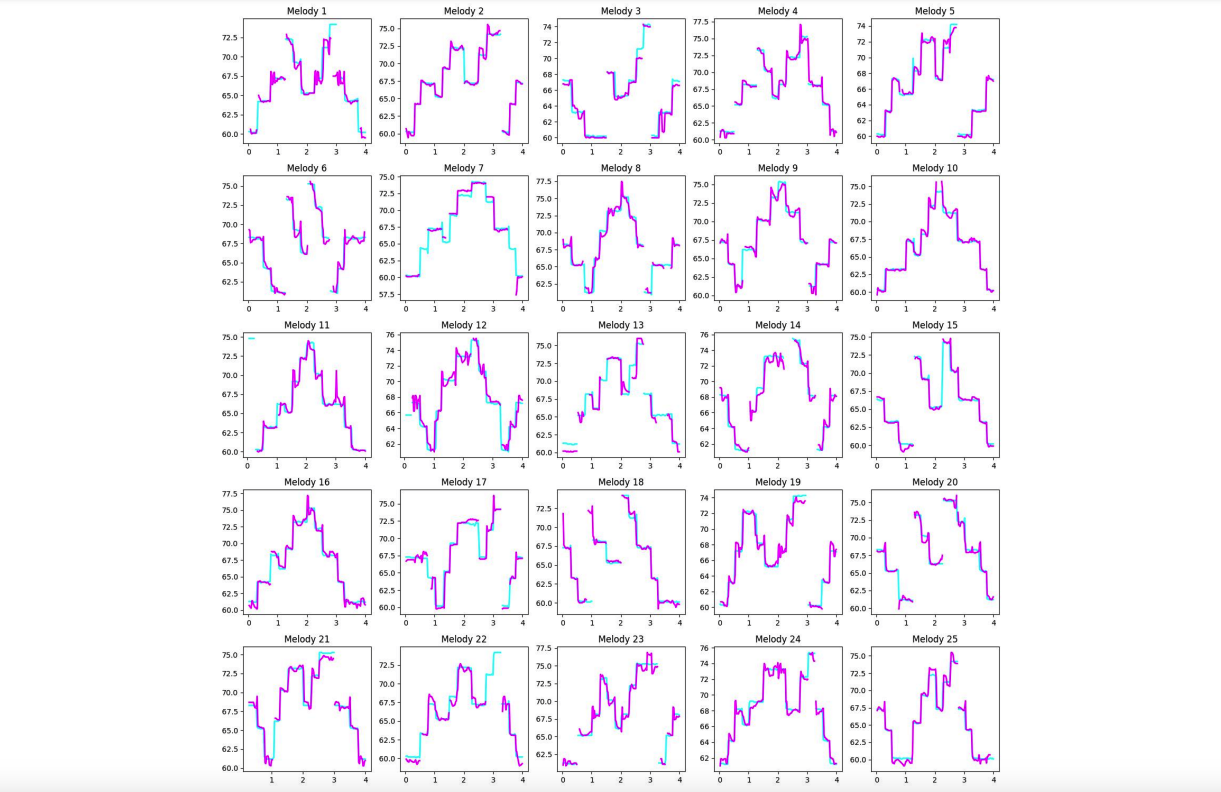
尽管论文中涉及复杂的数学内容,但从示例和宣传片中可以看出,Fugatto 将每个音频特征视为可调的连续体,而非简单的二元选择。例如,在融合吉他和流水的声音时,用户可以调节各自的权重,从而得到不同的结果。此外,Fugatto 还能够执行多种音频任务,如改变文本情感、分离音乐中的人声、识别 MIDI 音乐中的单个音符并替换为不同演唱表演。
研究人员将Fugatto视为朝向无监督多任务学习未来的一步,英伟达也在讨论其应用案例,包括歌曲原型制作、动态视频游戏配乐和国际广告定位。英伟达强调,Fugatto应被视为音频艺术家的新工具,而非替代他们创作才能的工具。英伟达 Inception 项目参与者 Ido Zmishlany 指出,随着 AI 的发展,我们正在书写音乐的新篇章,Fugatto 为音乐创作提供了新的可能性。
关注 TopsTip:X/Twitter

