OpenAI 发布了新的 AI 模型 – CriticGPT,旨在识别由 ChatGPT 生成的代码中的错误。通过 Reinforcement Learning from Human Feedback (RLHF:来自人类反馈的强化学习),CriticGPT 可以帮助人类审查员提高大语言模型 (LLM) 的输出准确性。

由于模型变得更有知识,错误变得更加微妙,人类培训师难以准确评估。而 CriticGPT 是基于 GPT-4 的模型,用于撰写 ChatGPT 响应的批评,用以帮助人类培训师在 RLHF 过程中发现错误。
CriticGPT 训练方式
CriticGPT 的训练方式与 ChatGPT 类似,使用 RLHF,但重点是批评包含故意错误的输入。AI 培训师手动在 ChatGPT 代码中插入错误并提供示例反馈。CriticGPT 的表现通过评估插入的和自然发生的错误来衡量。由于 CriticGPT 产生的无用批评和幻觉问题更少,其批评在 63% 的情况下比 ChatGPT 的批评更受欢迎。

优势
- 增强培训师表现:使用 CriticGPT 的培训师能产生更全面的批评并捕捉更多错误;
- 减少幻觉:CriticGPT 帮助减少与模型单独工作时相比的虚假错误;
- 改进 RLHF 数据:在 RLHF 过程中使用 CriticGPT 有助于生成更高质量的 GPT-4 训练数据。
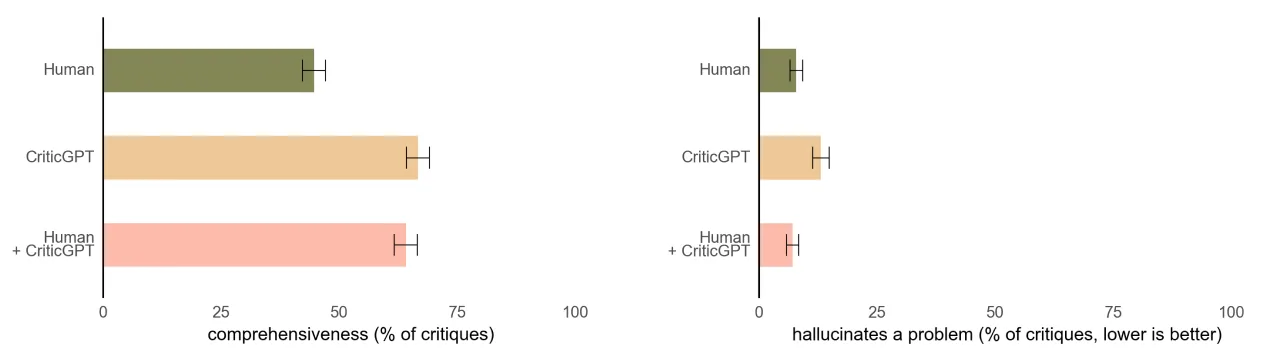
以上左图比较了“人类(绿色)”、“CriticGPT(橙色)”和“人类与 CriticGPT(粉色)”对代码批评的完整性。可以看出,CriticGPT 的批评比人类的批评更全面。
以上右图比较了“代码批评中包含虚假信息(幻觉)的比例”。可以看出,人类使用 CriticGPT 时,虚假信息的比例最低。
限制
- 短答案:CriticGPT 在短的 ChatGPT 答案上进行训练,未来需要处理更长更复杂的任务;
- 幻觉:模型和培训师仍可能因幻觉而犯错误;
- 复杂错误:当前关注的是单点错误,未来需要解决分散在多个部分的错误;
- 复杂性限制:即使是专家和模型辅助,极其复杂的任务仍可能难以评估。
OpenAI 计划将 CriticGPT 类模型进一步整合到他们的 RLHF 标注流程中,以更好地对齐日益复杂的 AI 系统。这包括进一步的研究和实际应用,以改进评估高级 AI 输出的工具。
-=||=-收藏赞 (2)

